정규 표현식 파이썬 예제를 통한 데이터 전처리 실제 활용- [데이터 전처리]
정규표현식
특정한 규칙을 가진 문자열의 집합을 표현하는데 사용하는 언어 형식
※ 생각보다 데이터 전처리 할 때 많이 유용할 것 같아 따로 공부하고 정리해본다.
사용예시
1. 이름 데이터중 남여 성별을 나누고 싶을 때
name = 'Miss Kim'
name2 = 'Mr Kim'
test = re.compile('[A-Za-z]+')
print(test.match(name))
print(test.match(name2))
2. 다른 문자를 제거하고 전화번호만 뽑고 싶을 때
source = "@!!asd Skywarker!@ 02-123-4567 luke@daum.net"
test = re.compile('[0-9-]+')
print(test.findall(source))

메타 문자
| [] | . | * | + | {m, n} | ? | | | ^ | $ | ( ) |
1. [ ]
- [ ] 안에 들어간 문자끼리는 OR로 연결된다.
- 데이터의 규칙을 찾아 [ ] 안에 알맞은 문자를 넣어 표현.
source = "my phone number 010-1234-5678"
test = re.compile('[0-9-]+')
print(test.findall(source))
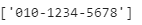
[0-9-] : 숫자 0~9, '-' 이 들어간 문자열 출력
※ [ ]안에 어떤 조건을 넣는지가 중요
원래 표현식축약 표현부연 설명사용처
2. 문자 클래스
| [0-9] | \d | 숫자를 찾는다 | 숫자 |
| [^0-9] | \D | 숫자가 아닌 것을 찾는다 | 텍스트 + 특수문자 + 화이트스페이스 |
| [ \t\n\r\f\v] | \s | whitespace 문자인 것을 찾는다 | 스페이스, TAB, 개행(new line) |
| [^ \t\n\r\f\v] | \S | whitespace 문자가 아닌 것을 찾는다 | 텍스트 + 특수문자 + 숫자 |
| [a-zA-Z0-9] | \w | 문자+숫자인 것을 찾는다. (특수문자는 제외. 단, 언더스코어 포함) | 텍스트 + 숫자 |
| [^a-zA-Z0-9] | \W | 문자+숫자가 아닌 것을 찾는다. | 특수문자 + 공백 |
source = "my phone number 010-1234-5678"
test = re.compile('[\D]+')
print(test.findall(source))
'[\D]+' : 숫자가 아닌것들을 출력
3. .(dot)
dot은 문자 사이매칭
source = "my phone number 010-1234-5678"
test = re.compile('n..')
print(test.findall(source))
test = re.compile('m......e')
print(test.findall(source))
test = re.compile('1..4')
print(test.findall(source))

n.. : n뒤에 3개 문자열 출력
m.....e : m에서 시작해서 e까지 끝나는 문자열 출력 (가운데 .(dot)의 갯수 만큼 넣어야함)
4. *
앞에 문자가 0번 이상 반복
source = "fast naaav naaaaave naaaavvaav"
test = re.compile('aa*')
print(test.findall(source))
source2 = "fbst nbaaav nbaaaaave nbaaaavvaav"
test2 = re.compile('ba*')
print(test.findall(source2))

'aa*' : a로 시작하고 *앞의 단어인 a가 0번 이상 반복되는 것 출력
※ fast는 'f', 'a', 's', 't' 로 이루어져 있고 'a', 's' 구간에서 a로 시작하고 그 다음 a가 없어 a만 출력
'ba*' : b로 시작하고 *앞의 단어 a가 0번 이상 반복 출력
※ fbst는 'b', 's' 구간에서 b로 시작하고 a가 없어 b만 출력
5. +
앞의 문자가 1번 이상 반복
source2 = "fbst nbaaav nbaaaaave nbaaaavvaav"
test2 = re.compile('ba+')
print(test2.findall(source2))
'ba+' : b로 시작하고 a가 하나 이상 있는 단어의 a연속되어 출력
실제로 어떻게 사용되나
'[A-Za-z]+' : [대문자, 소문자로 이루어진 문자열중] 단어들을 나누어 출력
'[A-Za-z]*' : [대문자, 소문자로 이루어진 문자열중] 단어들을 나누어 출력하지만 이외의 문자(숫자, 특수문자, 공백등) 은 ''로 출력
'[A-za-z]+.v' : [대문자, 소문자로 이루여진 문자열중] 단어들을 나누어 출력해, 끝이 v로 끝나는 단어만 출력
source = "fbst nbaa123av nbaaaaave nbaaaavvaav"
test1 = re.compile('[a-z]+')
print(test1.findall(source))
test2 = re.compile('[a-z]*')
print(test2.findall(source))
test3 = re.compile('[a-z]*.v')
print(test3.findall(source))
6. {m, n}
앞의 단어가 m이상, n이하 반복되는 것 출력
source = "fbst nbaa123av nbaaaaave nbaaaavvaav"
test1 = re.compile('a{1,2}v')
print(test1.findall(source))
# nbaa123'av', nbaaa'aav'e, nbaa'aav'v'aav' 작은따옴표로 표시된 부분 출력
a{1,2}v : a가 1개 이상, 2개이하 있는 문자열에서 v로 끝나는 단어 출력
7. ?
앞의 단어가 있거나, 없어도 될 경우
source = "fbst nbaa123av nbaaaaave nbaaaavvaav naaanaa"
test2 = re.compile('nb?a*')
print(test2.findall(source))
'nb?a*' : 문자가 n으로 시작하고 b이거나, b가 아예 없고 a로 끝나는 단어중 a가 0번 이상 반복되는 단어 출력
naaanaa는 n으로 시작하고 b가 없이 바로 a로 이어져 있어 'naaa' 출력
8. ^ $
^ 맨 처음에 와야하는 단어
% 맨 마지막에 와야하는 단어
source = "you and your and youth"
test1 = re.compile('^you')
print(test1.findall(source))
test2 = re.compile('youth$')
print(test2.findall(source))※ 전처리 할 때 ^$ 는 어떻게 쓸지 감이잘 오지 않는다..어떻게 응용할지는 차차 생각해보자
Pandas에서 정규 표현식 활용
| col1 | col2 | |
| 0 | apple made in Korean. | 50 |
| 1 | grape made in American. | 60 |
df['col3'] = df['col1'].str.extract('([A-Za-z]+)\.')col3새로운 열을 만들어 맨뒤의 원산지 데이터를 추가
탐색 메서드
match, search, findall, finditer
match - 문자열중 처음과 일치하지 않으면 None반환
Search - 문자열중 일치하는 문자를 전체중에서 가장 앞에것 하나 찾고 끝냄
findall - 문자열중 해당하는 문자를 계속해서 찾음
finditer - finall과 같은 방식이지만, iterator로 반환함
정규 표현식을 연습해보는 사이트
RegExr: Learn, Build, & Test RegEx
RegExr is an online tool to learn, build, & test Regular Expressions (RegEx / RegExp).
regexr.com