
Classification 분류
- 분류를 이해하기
- Classification 특성과 알고리즘
- 분류의 다양한 방식을 알아보기
- Logistic Regression
- SoftMax
- Naive Bayes
- SVM
분류이해하기
분류 : 카테고리에 분류하는 방식 // 선형회귀는 분류에 사용 될 수 없음
- 분류는 0 또는 1의 값만 가지기 때문에 그 범위 이상의 값을 가질 수 없음.
ex) 종양 크기를 통해 암 유무를 확인할때 선형회귀를 사용한다 치면 종용의 크기 데이터 하나의 값이 지나치게 다를경우 중간에 분류할 값을 찾기 힘들어 분류에 오류가 생김 고로 다른 모델을 사용 해야함 https://wikidocs.net/4288
Logistic Regression
0~1 사이의 값만 보내는 함수가 필요 0 <= h(x) <= 1
Sigmoid function

h(x) = P(y=1|x;0) // 1번 class에 들어갈 확률
Decision Boundary
Hypothesis function 의 값 0.5를 기준으로 분류
- -X값이 0보다 크면 시그모이드 함수는 1값에 가까워 지고
- -X값이 0보다 작으면 시그모이드 함수는 0값에 가까워 진다
Cost function
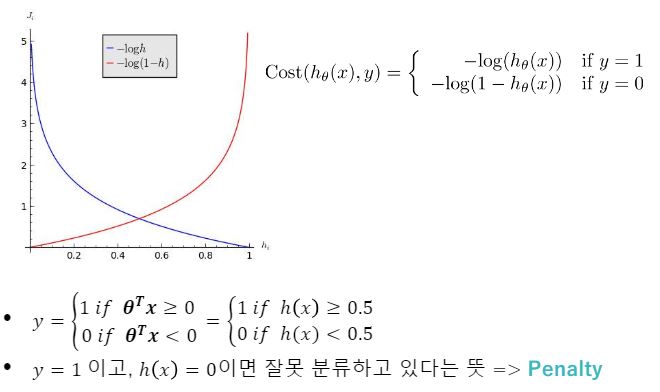
이말은 Θx값이 0보다 크거나 같으면 1로 작으면 0으로 수렴한다 http://gnujoow.github.io/ml/2016/01/29/ML3-Logistic-Regression/
Softmax function , Multinomial classfication
분류를 해야할 것이 3개 이상일때 어떻게 분류할 것인가??
A,B,C 3개의 클래스가 있을때
- A인가 아닌가로 : A판별 // X - A - Y
- B인가 아닌가로 : B판별 // X - B - Y
- C인가 아닌가로 : C판별 // X - C - Y

Cross Entropy
예측값과 Label 값이 얼마나 차이가 있는지 나타내는 척도

Cost function을 구한 것
L 은 실제값 Y는 예측값
- 요소끼리 곱을 진행한다
- 0혹은 1의 값이 나오면 맞는 것이고 무한대로 수렴하면 틀린 값
Support vector machine
다양한 데이터 분포 에서도 동작하는 분류 기법중 하나이다.
- 두 분류 직선을 가르는데 이 둘 사이의 거리인 마진을 최대화하는 분류 경계면을 찾는 기법.
- SVM은 최대 마진을 가지는 선형 판별에 기초해, 속성들 간의 의존성을 고려하지https://i.imgur.com/afe8W3S.png 않는 방법
{kind=link}
Decision Rule
우리가 그릴 street의 중심선에 직교하는 벡터 w
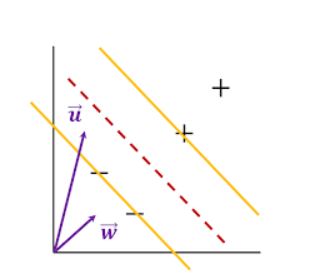
w 와 u 의 내적을 구한 후 그 값이 어떤 상수보다 큰지 확인 하는것 http://jaejunyoo.blogspot.com/2018/01/support-vector-machine-1.html https://ratsgo.github.io/machine%20learning/2017/05/23/SVM/
SVM 증명과 원리는 나중에 자세하게 다시 한번 정리하기로 함 (좀 많이 복잡해서 여유 있을때 정리하기로 한다.)
'공부 > AI School 인공지능 여름캠프' 카테고리의 다른 글
| 딥러닝 시작, 신경망 기초 - [AI School] (0) | 2021.05.03 |
|---|---|
| 머신러닝 의사결정트리(Decision Tree), 앙상블, 엔트로피 - [AI School] (0) | 2021.05.03 |
| 머신러닝 회귀(Regression) 정리 - [AI School] (0) | 2021.05.03 |
| 파이썬 사이킷 런(sklearn) 이용 - [AI School] (0) | 2021.05.03 |
| 탐색적 데이터 분석(EDA) 정리 - [AI School] (0) | 2021.05.03 |