
워드 임베딩
워드 임베딩이란?
텍스트 분석을 위해서 단어를 표현하는 데 사용되는 용어로, 일반적으로 벡터 공간에서 더 가까운 단어가 예상되도록 단어의 의미를 벡터 형식으로 표현하는 방법
※ 크게 희소표현과 밀집표현의 형태로 나눌 수 있다.
희소 표현
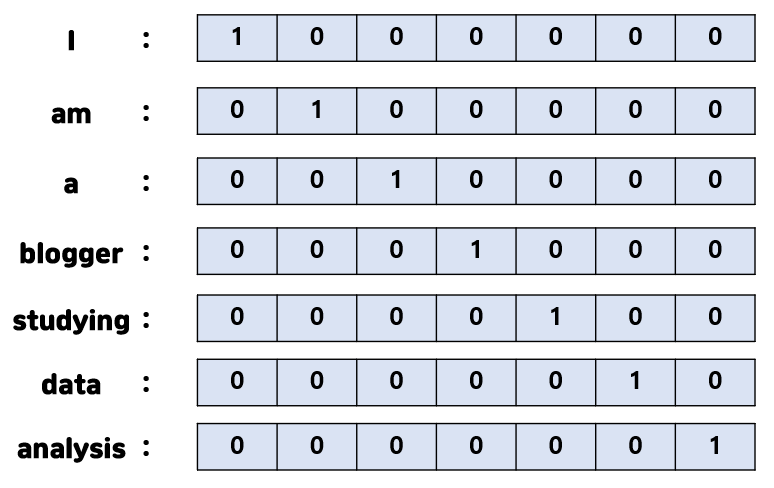
문장을 벡터로 표현 할 때, 표현하고자 하는 단어의 인덱스 값이 1이고, 나머지 값들이 전부 0과 같은 희소행렬 방식으로 표현된 방법.
희소행렬 - 대부분의 행렬 값이 0을 가리키는 표현
자연어 에서는 원-핫 인코딩과 같은 방식을 희소 표현이라고 표현
예제)
"나는 오늘부터 자연어 처리 공부한다" 라는 문장을 표현시
{ 나는 : 3, 오늘부터 : 1, 자연어 : 2, 처리 : 5, 공부한다 : 4 }
[[0. 0. 1. 0. 0]
[1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0.]
[0. 0. 0. 0. 1.]
[0. 0. 0. 1. 0.]]
위와 같은 방식으로 표현을 진행하면, 문장이 길어질 수록 단어가 늘어나 차원이 늘어나기 때문에 무분별하게 0의 갯수가 늘어나 공간적인 낭비가 된다는 단점을 가지고 있다.
밀집 표현
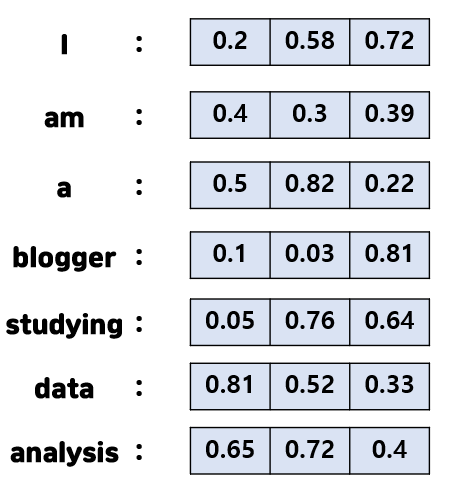
밀집 표현은 희소 표현과 다르게 벡터의 차원을 문장의 단어 크기 및 갯수 로 정하지 않고, 사용자가 임의로 설정한 값으로 차원을 맞추어 실수 값을 넣는다.
예제)
문장내의 단어가 10,000개일 때, 사용자가 임의로 100차원으로 설정시
단어1 = [0.2 1.8 1.5 -2.1 1.1 2.8 ... 중략 ...] // 단어1의 100차원
단어2 = [ ... 중략 ... ]
.
.
.
단어10,000 = [ ... 중략 ... ]
※ 해당 문서를 희소표현으로 진행시, 단어1~단어10,000개 모두 [0. 0. 1. ...중략...0] 단어당 10,000개가 들어가야함
공간의 낭비가 너무심함, 따라서 밀집표현으로 하면 차원이 줄어들어 공간을 절약 할 수 있음.

'딥러닝 > 자연어처리' 카테고리의 다른 글
| TF-IDF (Term Frequency-Inverse Document Frequency) 정리 및 예제(키워드 추출) - [자연어 처리] (3) | 2021.12.22 |
|---|