
TF(Term Frequency)
1개의 문서안에서 특정 단어의 등장 빈도를 의미
문장을 단어로나누고, 전체 단어수가 얼마나 사용됐는디 파악해 문서의 종류를 분류하는 지표로 사용.
※ 1글자의 경우 생략하는 경우가 많음
DF(Document Frequency)
특정 단어가 나타나는 문서의 갯수를 의미
특정단어가 각 문선들에 몇 번 등장해는지는 신경쓰지 않고, 특정단어가 문서의 수에 등장했는지 안했는지만 관심을 가짐
※ 100개의 문서중 2개의 문서만 '반도체' 라는 단어가 등장하면, 그 문서안의 '반도체'가 100번, 200번 등장했는지는 관심없고 오로지 'DF(반도체') == 2를 의미함
IDF(Inverse Document Frequency)
특정 단어 모든 문서에 등장하는 흔한 단어라면, 이를 방지하기 위해 TF-IDF 가중치를 낮추기 위해 역수를 취한 값
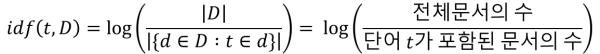
※ 전체 문서가 많을 수록 값이 커져, 정규성을 높이고 분석(회귀분석 등)에서 정확한 값을 얻기 위해 Log를 취함

※ 1을 더하는 이유는 단어가 포함된 문서가 없을 경우 분모가 0이 되어버리기 때문에 이를 방지하기위해 1을 더함

빈도수가 많이 발생할 수록 IDF값이 낮아지는 것을 확인가능
TF - IDF(Term Frequency - Inverse Document Frequency)
TF - IDF는 TF, IDF 두 수치를 곱한 값
특정 단어가 한 문서에 몇 번 언급되며, 문서군에서는 얼마나 등장하였는지를 표현한 가중치

TF - IDF 예제
- TF - IDF를 통해서 문서내에서 주로 사용된 단어, 의미있는 단어를 찾아 주제등을 유추가능
- 핵심어 추출을 통해서 각 문서들의 비슷한 정도를 유추가능
1) 사용 데이터 셋 소개 : "AI Hub"의 특허자료 : 요약문(초록) 문장단위, 청구항
전문분야 말뭉치
상대적으로 성능 확보가 어려운 전문 분야에 대한 자연어 처리(Natural Language Processing) 학습용 말뭉치 데이터 구축
aihub.or.kr

2) 특허 데이터중 "반도체"관련 특허에 대한 데이터만 추출
2-1 총 696개의 반도체 관련 특허 문서가 존재하였고 각 문서별 중요 단어 추출

2-2 index 0인 문서를 확인해본 결과 한 3,042개의 단어가 수집되어있으며 tf값을 추출하기 위해 중복 단어도 포함되어있음.

3) 데이터 중 결측치 제거
특수문자, 숫자로만 구성된 단어, 1글자 단어제거
test = []
for doc in ptdf['patent_words']:
for word in doc:
# 특수문자, 숫자로만 구성된 단어, 1글자 단어
if word.isalnum() == False or word.isdigit() == True or len(word) == 1:
# print("특수")
continue
test.append(word)
# 등장 단어리스트 추출
vocab = list(set(test))
vocab.sort()
4) tf 값 계산
각 문서별 등장 단어에 대한 tf값이 정리된 테이블 저장
def tf(t, d):
return d.count(t)
N = len(ptdf)
result = []
for i in tqdm.tqdm(range(N)): # 각 문서에 대해서 아래 명령을 수행
result.append([])
d = ptdf['patent_content'][i]
for j in range(len(vocab)):
t = vocab[j]
result[-1].append(tf(t, d))
tf_ = pd.DataFrame(result, columns = vocab)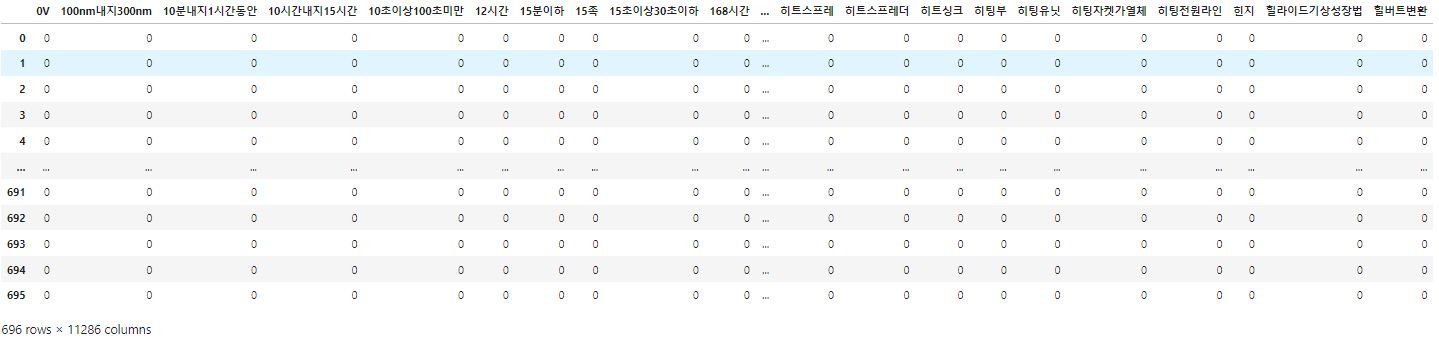
문서를 종합했을 때 단어가도체, 반도체라는가장많이 등장함

5) idf값 계산
idf값은 모든 특허문서에 해당 단어가 자주 등장하게 된다면 idf의 분모값(한 단어가 모든 특허 문서에서 등장하는 횟수)이 올라가 idf값이 낮아질 것이고,
반대로 모든 특허문서에 해당 단어가 적게 등장한다면 idf값은 높지만 tf(특허당 단어의 빈도수)값은 낮아지기 때문에 추후 tf-idf값이 낮아지기 때문에 가지치기 당하게 된다.
from math import log
def idf(t):
df = 0
for doc in ptdf['patent_words']:
df += t in doc
return log(N/(df + 1))
result = []
for j in range(len(vocab)):
t = vocab[j]
result.append(idf(t))
idf_ = pd.DataFrame(result, index = vocab, columns = ["IDF"])
6) tf-idf 값 계산
tf-idf값은 tf값과 idf값이 적절하게 존재해야 값이 높아진다.
tf(단어의 빈도수)값이 높지만, idf(전체문서/1 + 모든 특허문서에 해당 단어 등장하는 횟수)값이 낮으면 모든 문서에 흔하게 등장한다고 생각할 수 있고
반대로 idf(전체문서/1 + 모든 특허문서에 해당 단어 등장하는 횟수)값이 지나치게 높으면 해당단어는 여러 특허문서에 분포되어 있지 않다고 생각할 수 있다.
def tfidf(t, d):
return tf(t,d)* idf(t)
result = []
for i in tqdm.tqdm(range(N)):
result.append([])
d = ptdf['patent_words'][i]
for j in range(len(vocab)):
t = vocab[j]
result[-1].append(tfidf(t,d))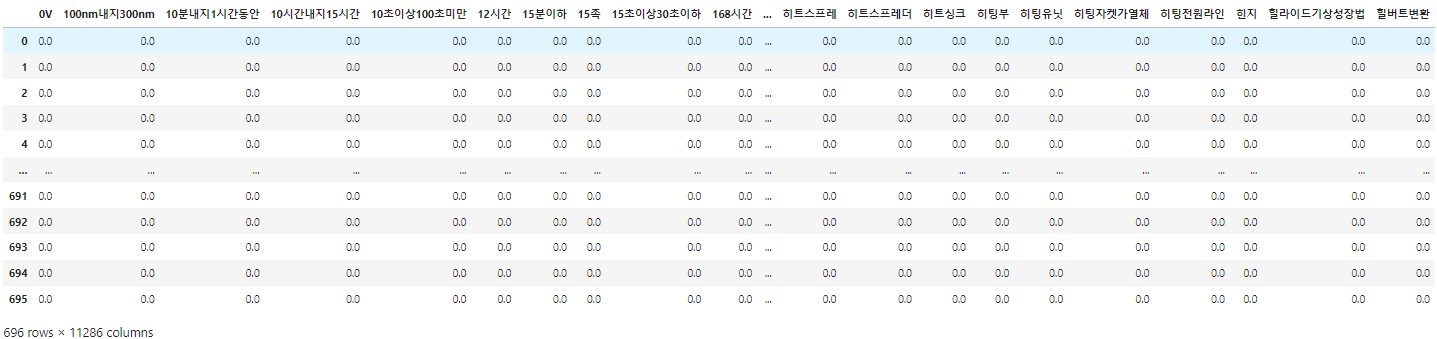
테이블을 뽑아본결과 단어들의 컬럼이 너무많아 tf-idf값의 가중치의 합을 구해본결과 모든 '반도체' 특허 문서에서 나오는 중요 단어 키워드들을 뽑아볼 수가 있었다.


'딥러닝 > 자연어처리' 카테고리의 다른 글
| 워드 임베딩(Word Embedding),희소표현, 밀집표현 정리 - [자연어 처리] (0) | 2021.05.12 |
|---|