
< 교차검증 >
교차검증은 모델의 학습 과정에서 모델 생성을 위한 데이터셋을 학습(Training) / 검증(Validation) 데이터를 나눌 때 Validation데이터 셋에만 학습이 과적합 되어버리는 결과를 방지하기 위한 방법
* 즉, 내가 만든 모델을 평가 했을 때 내 Train 데이터 셋에만 결괏값이 잘 나오는 것을 방지하기 위함.
교차검증의 장점
- 모든 데이터 셋을 평가에 활용 가능
- 데이터의 편향적인 영향을 받지 않음
교차검증의 단점
- 역시나, 학습 횟수가 많아 훈련/평가 시간이 오래걸림.
HoldOut 방법
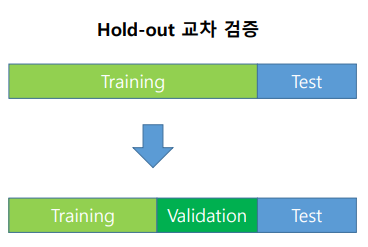
HoldOut 방식은 Train : Validation의 비율을 정해 사용하는 방식, 예를 들면 7:3의 비율을 정해놓고 모델 학습 진행
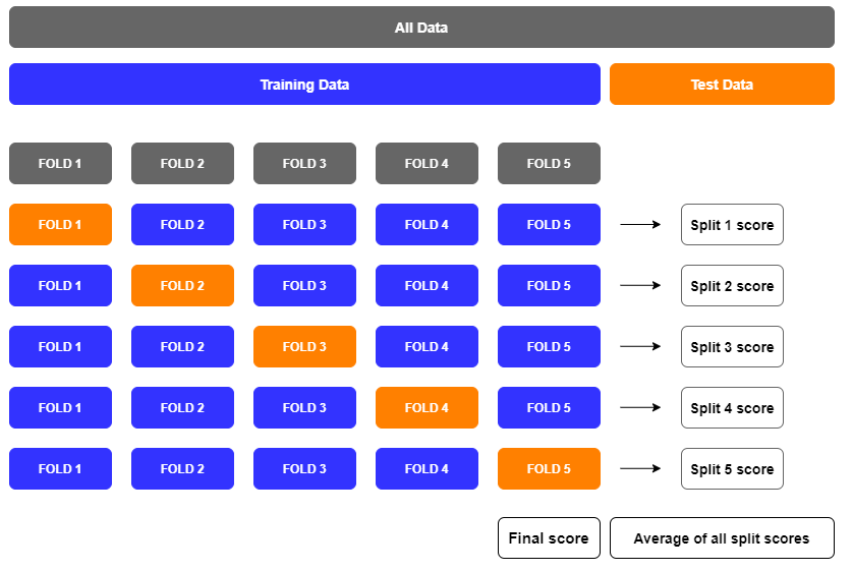
K-Fold 방법
모델의 학습 과정에서 모델 생성을 위한 데이터셋을 Train / Validation 데이터를 나눌 때
K개의 데이터 셋을 만든 후 K번만큼 학습과 검증을 수행하는 방법
import numpy as np
from sklearn.model_selection import KFold
X = np.arange(16).reshape((8,-1))
y = np.arange(8).reshape((-1,1))
kf = KFold(n_splits=6) #n개의 Fold로 나눔
for train,test in kf.split(X):
# print(train, test)
X_train,X_test = X[train], X[test]
Y_train,Y_test = y[train], y[test]
print(X_train)
print(X_test)K개만큼 나눠서 학습을 진행
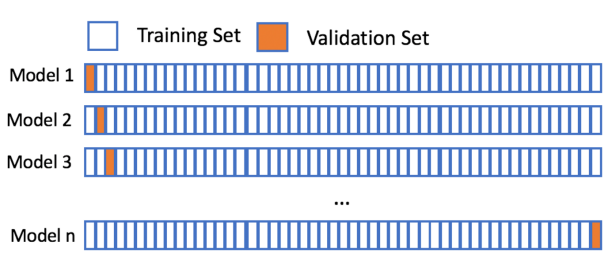
LOO (Leave One Out)
Validation set을 한 개로 하고, 나머지를 Train set으로 해서 하나씩 모두 검증하는 방식.
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
X = np.arange(16).reshape((8,-1))
y = np.arange(8).reshape((-1,1))
for train,test in loo.split(X):
print(train,test)
# X_train,X_test = X[train], X[test]
# Y_train,Y_test = y[train], y[test]
# print(X_train)LPO라는 검증 방식도 존재, LOO처럼 Validation set을 하나씩만이 아니라 P의 개수만큼 Validation set으로 사용
from sklearn.model_selection import LeavePOut
loo = LeaveOneOut()
# X = np.arange(16).reshape((8,-1))
# y = np.arange(8).reshape((-1,1))
lpo = LeavePOut(p=2)
for train,test in lpo.split(X):
# print(train,test)
X_train,X_test = X[train], X[test]
Y_train,Y_test = y[train], y[test]
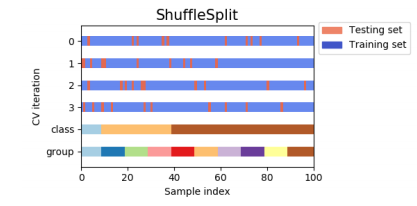
print(X_train)ShuffleSplit
Train set과 Validation Set의 크기를 유연하게 조절해야 할 때, Size를 조정해 임의로 섞어서 분할 검증하는 방식
from sklearn.model_selection import ShuffleSplit
# Testsize비율만큼 데이터 크기를 나누고, n_splits 만큼 교차검증 진행
# random_state는 성능에 영향을 미치진 않지만 일종의 기억장치 seed값으로 random값 저장
ss = ShuffleSplit(n_splits=5, test_size=0.25, random_state = 0 )
for train,test in ss.split(X):
print(train,test)
X_train,X_test = X[train], X[test]
Y_train,Y_test = y[train], y[test]
# print(X_train)TimeSeriesSplit
연속적인 데이터를 유지해야 하는 시계열 데이터의 경우 사용
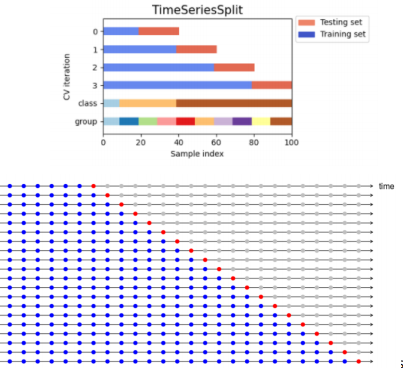
from sklearn.model_selection import TimeSeriesSplit
ts = TimeSeriesSplit(n_splits=7)
for train,test in ts.split(X):
print(train,test)
X_train,X_test = X[train], X[test]
Y_train,Y_test = y[train], y[test]
# print(X_train)아래와 같은 결과를 도출
[0] [1]
[0 1] [2]
[0 1 2] [3]
[0 1 2 3] [4]
[0 1 2 3 4] [5]
[0 1 2 3 4 5] [6]
[0 1 2 3 4 5 6] [7]
이외에도
- StratifiedKFold - 분류 문제에 많이 사용하는 교차검증
- GroupKFold - KFold에서 K개의 폴드를 그룹으로 묶어 사용
- GrouupShuffleSplit - ShuffleSplit + GroupKFold
< 타이타닉 데이터 교차검증 >

1. 전처리
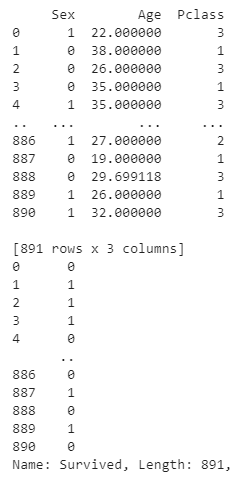
* 성별, 나이, 탑승등급 Features로 생존 Label로 사용
titanic['Sex'] = titanic['Sex'].map({'male':1,'female':0}).astype(int)* male == 1, female == 0 전처리
titanic_data = titanic[['Survived','Pclass','Sex','Age']]
titanic_data['Age'].fillna(titanic['Age'].mean(), inplace=True)
features = titanic_data[['Sex','Age','Pclass']]
Survival_data = titanic_data['Survived']* Age에 있는 NaN값들은 나이 평균을 이용해 값을 채워 넣음
2. 모델 학습
- 로지스틱 선형 회귀 사용
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
train_feature, test_feature, train_label, test_label = train_test_split(features, Survival_data, test_size=0.3)
model = LogisticRegression()
model.fit(train_feature, train_label)3. 모델 검증
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
pred_y = model.predict(test_feature)
print("정확도 : ",accuracy_score(pred_y, test_label))
print(confusion_matrix(test_label,pred_y))- 77~78%의 정확도
- Confusion_matrix를 통해
[132 25] 죽은 인원을 맞게 예측 한 수 132명 예측
[34 77] 생존한 인원을 맞게 예측 한 수 77명 예측
4. K-Fold사용
from sklearn.model_selection import KFold, cross_val_score
for i in range(5,15):
kf = KFold(n_splits=i, shuffle = True)
score = cross_val_score(model, features, Survival_data, cv = kf, scoring="accuracy")
print(score.mean())
- 79~80%의 정확도 예측 (1~2 % 확률로 정확도가 증가)
- 기존의 모델 검증과의 차이 결과 기존 데이터 자체가 고르게 분포되어 있음을 확인할 수 있음.
4.1 LeaveOneOut 사용
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
score = cross_val_score(model, features, Survival_data, cv = loo, scoring="accuracy")
print(score.mean())4.2 ShuffleSplit 사용
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import cross_val_score
ss = ShuffleSplit(n_splits=20, test_size=0.2, random_state = 2 )
score = cross_val_score(model, features, Survival_data, cv = ss, scoring="accuracy")
print(score.mean())'머신러닝 > 머신러닝 알고리즘' 카테고리의 다른 글
| 로지스틱 회귀 Logistic Regression, 로지스틱 손실 함수 Cost Function For Logistic 개념 및 정리 - [머신러닝] (0) | 2021.06.01 |
|---|---|
| 선형회귀 Linear Regression 개념 및 예제 학습 - [머신러닝] (0) | 2021.04.30 |
| SVM(Support Vector Machine) 서포트 벡터 머신 정리 - [머신러닝] (0) | 2021.04.27 |