
목차
텐서플로우 소개 사용법
1. 딥러닝 프레임워크 1. 텐서플로우의 특징
텐서플로우의 특징
- 텐서플로우는 풍부한 코드 수정없이 CPU, GPU모드로 동작 가능하다.
- 많은 데이터 처리가 가능하다 (이미지, 비디오, 음성)
// 텐선플로우도 좋아보이지만 파이토치도 좋아보인다.(언젠간 파이토치 써보자.)
Eager Execution
Eager Execution은 데이터를 직접 포인팅함. tf.session을 할 필요가 없음
Nmumpy와 호환성을 크게 높여 계산 그래프의 생성과 실행단계가 구분되지 않음 https://tensorflow.blog/2017/11/01/tensorflow-eager-execution/
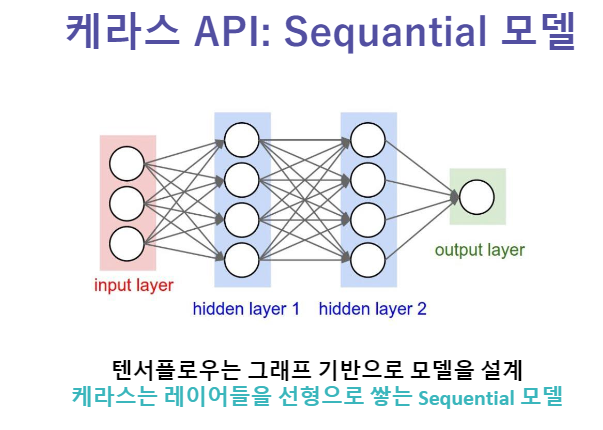
Sequantial 모델
from __future__ import absolute_import, division, print_function, unicode_literals
from tensorflow.keras import layers
import numpy as np
import tensorflow as tf
training_data =np.array([[0,0],[0,1],[1,0],[1,1]], 'float32')
target_data = np.array([[0],[1],[1],[0]], 'float32')
print(training_data)
model = tf.keras.Sequential() #Sequential모델 사용
model.add(layers.Dense(16, input_dim=2,activation='relu')) #레이어 추가
model.add(layers.Dense(1,activation = 'sigmoid'))
model.compile(loss='mse',
optimizer='adam',
metrics=['binary_accuracy'])
model.fit(training_data,target_data,nb_epoch=20)
#Tensorflow 데이터 생성 정리
#어째서 인지 주피터 노트북 에서는 eager execution이 활성화 되지 않는다.. 파이참은 되는데 뭐지..찾아본 결과 뭐 처음에 실행시켜주어야 작동 된다는데 자세하게는 잘 모르겠다..
import tensorflow as tf
import numpy as np
a = tf.constant(5) #
b = tf.constant(6) # 변수 정의 해주기
# tf.(zeros,ones,fill)([형태], dtype = tf.float32, name = '')
c = tf.zeros([3,3])
d = tf.ones([2,2])
e = tf.fill([2,2],4) # 2행 2열 4값으로 채워진 벡터 생성
#tf.(linspace, range)
f = tf.linspace(1.,12.,12) #(시작, 끝, num)
#여기서 num이 좀 애매함 stop-start / num-1 씩 증가 라는데
#시작과 끝은 소수점 이후의 값이 나오기 때문에 float만 해야함
g = tf.range(1.,10.,3.) #(시작, 끝값, 증가량)
#난수 설정
seed = tf.compat.v1.set_random_seed(100) # 난수 시드
h = tf.random.normal([4,4],mean = 0.0, seed = 100)
#mean 정규분포의 평균값 stddev 정규분포의 표준편차
i = tf.random.uniform([4,4], minval = 0, maxval = 5, seed = 99)
weight = tf.Variable(5, name = 'weight')
bias = tf.Variable(-3, name = 'bias')
model = tf.global_variables_initializer() #모델 내부 변수 초기화
with tf.Session() as session: # 값을 계산하기 위해 세션 생성
session.run(model) #모델 실행
for i in [a,b,c,d,e,f,g,h,i,weight,bias]:
print(session.run(i))
import tensorflow as tf
import matplotlib.pyplot as plt
# Tensorflow 1.8 Version
print(tf.__version__)
# 시각화 함수
def Visualize(x_data, y_data, hypothesis):
fig, ax = plt.subplots()
ax.grid()
ax.plot(x_data, hypothesis, 'r-')
ax.plot(x_data, y_data, 'o')
# 선형 데이터 x, y 선언
x_data = [1, 2, 3, 4, 5]
y_data = [1, 2, 3, 4, 5]
# 학습에 사용할 Weight, Bias 선언
W = tf.Variable(tf.random_uniform([1], -5.0, 5.0))
b = tf.Variable(tf.random_uniform([1], -5.0, 5.0))
# 입력이 들어갈 Placeholder (Input Node) 선언
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
# Cost 함수 설계
hypothesis = W * X + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# 학습 속도, Cost (Loss)를 줄여나가는 방법을 정하고 Optimizer를 선언합니다.
learning_rate = 0.005
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train = optimizer.minimize(cost)
# Session을 열어줍니다.
sess = tf.Session()
# Session 내의 전체 변수를 초기화
sess.run(tf.initializers.global_variables())
print(sess.run(W))
# 200번 학습 진행
for i in range(200):
# Train 객체에 학습 데이터 x_data와 Label 값 y_data를 입력합니다.
# 입력은 feed_dict로 딕셔너리 형태의 입력이 들어갑니다.
sess.run(train, feed_dict={X: x_data, Y: y_data})
if i % 15 == 0:
Visualize(x_data, y_data, sess.run(hypothesis, feed_dict = {X : x_data}))
print("Step : {}| Weight : {:.5f}| Bias : {:.5f}| Cost : {:.5f}".format(i,float(sess.run(W)), float(sess.run(b)), float(sess.run(cost, feed_dict={X: x_data, Y: y_data}))))
# Iteration이 끝나면 학습이 끝났습니다.
# 이제 검증 데이터로 학습된 hypothesis 성능을 평가합니다.
print(sess.run(hypothesis, feed_dict = {X : 5}))
print(sess.run(hypothesis, feed_dict = {X : 2.5}))
# 연산이 전부 끝났으면 Session을 닫아줍니다.
sess.close()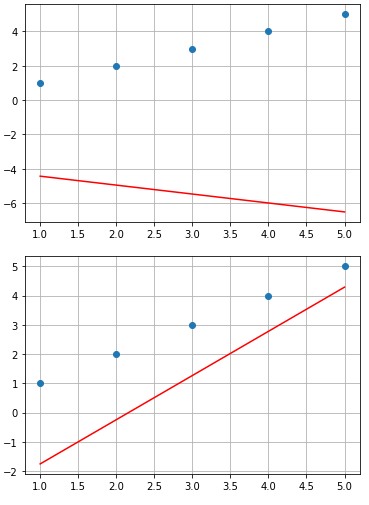
데이터 학습 #2
# Tensorflow + Keras
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow import keras
# 임의의 데이터 x, y를 선언합니다.
x = np.random.rand(10,1) # 0부터 1사이 균일분포하게 난수 생성한다. 100행 1열
y = 5 * x**2 + 3 * np.random.rand(1) # y는 X를 이용해 규칙을 주어서 생성
#Sequential하게 모델 선언 layers 쌓기 까지
model = keras.Sequential([
keras.layers.Dense(64, activation=tf.nn.relu, input_shape = (1, )),
keras.layers.Dense(32, activation=tf.nn.relu),
keras.layers.Dense(32, activation=tf.nn.relu),
keras.layers.Dense(1)
])
model.compile(optimizer='adam', loss='mse',metrics = ['mse','binary_crossentropy'])
history = model.fit(x,y, epochs = 500, batch_size = 100)
# 결과 출력
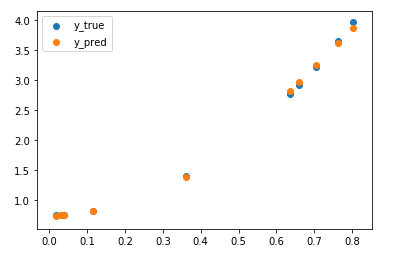
plt.scatter(x, y, label='y_true')
plt.scatter(x, model.predict(x), label='y_pred')
plt.legend()
'공부 > AI School 인공지능 여름캠프' 카테고리의 다른 글
| 딥러닝 심층 신경망 최적화, 기울기소실(Gradient Vanishing) - [AI School] (0) | 2021.05.04 |
|---|---|
| 딥러닝 ANN(Artificial Neural Network), 손실함수, 역전파법 (0) | 2021.05.03 |
| 딥러닝 시작, 신경망 기초 - [AI School] (0) | 2021.05.03 |
| 머신러닝 의사결정트리(Decision Tree), 앙상블, 엔트로피 - [AI School] (1) | 2021.05.03 |
| 머신러닝 분류 Classification - [AI School] (0) | 2021.05.03 |
텐서플로우 소개 사용법
1. 딥러닝 프레임워크 1. 텐서플로우의 특징
텐서플로우의 특징
- 텐서플로우는 풍부한 코드 수정없이 CPU, GPU모드로 동작 가능하다.
- 많은 데이터 처리가 가능하다 (이미지, 비디오, 음성)
// 텐선플로우도 좋아보이지만 파이토치도 좋아보인다.(언젠간 파이토치 써보자.)
Eager Execution
Eager Execution은 데이터를 직접 포인팅함. tf.session을 할 필요가 없음
Nmumpy와 호환성을 크게 높여 계산 그래프의 생성과 실행단계가 구분되지 않음 https://tensorflow.blog/2017/11/01/tensorflow-eager-execution/
Sequantial 모델
from __future__ import absolute_import, division, print_function, unicode_literals
from tensorflow.keras import layers
import numpy as np
import tensorflow as tf
training_data =np.array([[0,0],[0,1],[1,0],[1,1]], 'float32')
target_data = np.array([[0],[1],[1],[0]], 'float32')
print(training_data)
model = tf.keras.Sequential() #Sequential모델 사용
model.add(layers.Dense(16, input_dim=2,activation='relu')) #레이어 추가
model.add(layers.Dense(1,activation = 'sigmoid'))
model.compile(loss='mse',
optimizer='adam',
metrics=['binary_accuracy'])
model.fit(training_data,target_data,nb_epoch=20)#Tensorflow 데이터 생성 정리
#어째서 인지 주피터 노트북 에서는 eager execution이 활성화 되지 않는다.. 파이참은 되는데 뭐지..찾아본 결과 뭐 처음에 실행시켜주어야 작동 된다는데 자세하게는 잘 모르겠다..
import tensorflow as tf
import numpy as np
a = tf.constant(5) #
b = tf.constant(6) # 변수 정의 해주기
# tf.(zeros,ones,fill)([형태], dtype = tf.float32, name = '')
c = tf.zeros([3,3])
d = tf.ones([2,2])
e = tf.fill([2,2],4) # 2행 2열 4값으로 채워진 벡터 생성
#tf.(linspace, range)
f = tf.linspace(1.,12.,12) #(시작, 끝, num)
#여기서 num이 좀 애매함 stop-start / num-1 씩 증가 라는데
#시작과 끝은 소수점 이후의 값이 나오기 때문에 float만 해야함
g = tf.range(1.,10.,3.) #(시작, 끝값, 증가량)
#난수 설정
seed = tf.compat.v1.set_random_seed(100) # 난수 시드
h = tf.random.normal([4,4],mean = 0.0, seed = 100)
#mean 정규분포의 평균값 stddev 정규분포의 표준편차
i = tf.random.uniform([4,4], minval = 0, maxval = 5, seed = 99)
weight = tf.Variable(5, name = 'weight')
bias = tf.Variable(-3, name = 'bias')
model = tf.global_variables_initializer() #모델 내부 변수 초기화
with tf.Session() as session: # 값을 계산하기 위해 세션 생성
session.run(model) #모델 실행
for i in [a,b,c,d,e,f,g,h,i,weight,bias]:
print(session.run(i))
import tensorflow as tf
import matplotlib.pyplot as plt
# Tensorflow 1.8 Version
print(tf.__version__)
# 시각화 함수
def Visualize(x_data, y_data, hypothesis):
fig, ax = plt.subplots()
ax.grid()
ax.plot(x_data, hypothesis, 'r-')
ax.plot(x_data, y_data, 'o')
# 선형 데이터 x, y 선언
x_data = [1, 2, 3, 4, 5]
y_data = [1, 2, 3, 4, 5]
# 학습에 사용할 Weight, Bias 선언
W = tf.Variable(tf.random_uniform([1], -5.0, 5.0))
b = tf.Variable(tf.random_uniform([1], -5.0, 5.0))
# 입력이 들어갈 Placeholder (Input Node) 선언
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
# Cost 함수 설계
hypothesis = W * X + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
# 학습 속도, Cost (Loss)를 줄여나가는 방법을 정하고 Optimizer를 선언합니다.
learning_rate = 0.005
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train = optimizer.minimize(cost)
# Session을 열어줍니다.
sess = tf.Session()
# Session 내의 전체 변수를 초기화
sess.run(tf.initializers.global_variables())
print(sess.run(W))
# 200번 학습 진행
for i in range(200):
# Train 객체에 학습 데이터 x_data와 Label 값 y_data를 입력합니다.
# 입력은 feed_dict로 딕셔너리 형태의 입력이 들어갑니다.
sess.run(train, feed_dict={X: x_data, Y: y_data})
if i % 15 == 0:
Visualize(x_data, y_data, sess.run(hypothesis, feed_dict = {X : x_data}))
print("Step : {}| Weight : {:.5f}| Bias : {:.5f}| Cost : {:.5f}".format(i,float(sess.run(W)), float(sess.run(b)), float(sess.run(cost, feed_dict={X: x_data, Y: y_data}))))
# Iteration이 끝나면 학습이 끝났습니다.
# 이제 검증 데이터로 학습된 hypothesis 성능을 평가합니다.
print(sess.run(hypothesis, feed_dict = {X : 5}))
print(sess.run(hypothesis, feed_dict = {X : 2.5}))
# 연산이 전부 끝났으면 Session을 닫아줍니다.
sess.close()
데이터 학습 #2
# Tensorflow + Keras
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow import keras
# 임의의 데이터 x, y를 선언합니다.
x = np.random.rand(10,1) # 0부터 1사이 균일분포하게 난수 생성한다. 100행 1열
y = 5 * x**2 + 3 * np.random.rand(1) # y는 X를 이용해 규칙을 주어서 생성
#Sequential하게 모델 선언 layers 쌓기 까지
model = keras.Sequential([
keras.layers.Dense(64, activation=tf.nn.relu, input_shape = (1, )),
keras.layers.Dense(32, activation=tf.nn.relu),
keras.layers.Dense(32, activation=tf.nn.relu),
keras.layers.Dense(1)
])
model.compile(optimizer='adam', loss='mse',metrics = ['mse','binary_crossentropy'])
history = model.fit(x,y, epochs = 500, batch_size = 100)
# 결과 출력
plt.scatter(x, y, label='y_true')
plt.scatter(x, model.predict(x), label='y_pred')
plt.legend()
'공부 > AI School 인공지능 여름캠프' 카테고리의 다른 글
| 딥러닝 심층 신경망 최적화, 기울기소실(Gradient Vanishing) - [AI School] (0) | 2021.05.04 |
|---|---|
| 딥러닝 ANN(Artificial Neural Network), 손실함수, 역전파법 (0) | 2021.05.03 |
| 딥러닝 시작, 신경망 기초 - [AI School] (0) | 2021.05.03 |
| 머신러닝 의사결정트리(Decision Tree), 앙상블, 엔트로피 - [AI School] (1) | 2021.05.03 |
| 머신러닝 분류 Classification - [AI School] (0) | 2021.05.03 |